最强模型发布了,但中国开发者的焦虑才刚开始
导语
2025年12月,OpenAI发布了迄今最强的代码模型——GPT-5.2-Codex。它能处理百万行级别的代码库,具备更强的安全防护能力,被视为全球开发者的生产力革命。然而,中国开发者的第一反应却不是欢呼,而是担忧:闭源与访问限制,是否意味着“最强模型,却可能是最远的工具”?
这篇文章将从事件本身、矛盾张力、全球趋势、中国开发者的现实困境,到未来三年的窗口期,全面剖析这场技术突破背后的风险与机遇。

一、事件本身:GPT-5.2-Codex的突破
OpenAI在发布会上强调,GPT-5.2-Codex具备三大核心能力:
- 超大代码库处理:能够跨文件理解与重构百万行级别的项目。
- 安全防护升级:内置漏洞检测与合规审查,减少生成不安全代码的风险。
- 开发体验优化:与主流IDE深度集成,支持多语言、多框架的智能补全。
第三方测试数据显示,在HumanEval基准上,GPT-5.2-Codex的准确率超过90%,远高于上一代模型。同时,它在GitHub Copilot的集成测试中,显著提升了开发效率。
这不仅是一次模型迭代,而是一次生产力范式转移:开发者从“写代码”转向“写意图”,从“调试错误”转向“验证安全”,工作方式被彻底重塑。
二、矛盾张力:突破与封锁的双重现实
然而,中国开发者的焦虑并非空穴来风。
- 访问限制:OpenAI的API在中国大陆无法直接注册与支付,部分功能受限。
- 闭源策略:模型不开源,权重不可获取,意味着无法在本地部署。
- 合规风险:跨境调用涉及数据出境与隐私合规,企业难以大规模采用。
这形成了鲜明的矛盾:技术突破的浪潮正在席卷全球,但中国开发者却可能被挡在门外。
有人会说,封锁并非绝对,仍可通过代理或合作渠道使用。但问题在于,这种方式无法形成稳定、可控的生产力体系。对企业而言,风险与成本过高。

三、全球趋势:算力与模型的战略竞争
要理解这场矛盾,必须放在全球趋势中。
- 算力竞争:NVIDIA GPU仍是稀缺资源,美国限制高端芯片出口,中国加速国产替代。
- 模型竞争:OpenAI、Anthropic、Google DeepMind频繁迭代,国内阿里、百度、华为也在追赶。
- 开源生态:Meta的LLaMA、国内的Qwen等开源模型降低了门槛,但在代码场景仍有差距。
- 资本投入:全球AI投资规模持续增长,形成“算力+模型+生态”的三位一体竞争格局。
趋势清晰:AI模型正在成为战略资源,技术壁垒正在形成。算力决定上限,数据决定拟合速度,分发决定生态锁定。中国开发者的担忧,正是这种趋势的直接投射。

四、中国开发者的现实困境
从开发者的日常体验来看,困境具体而真实:
- 工具不可用:无法直接接入GPT-5.2-Codex,导致效率差距。
- 替代品不足:国内已有通义灵码、百度Comate等工具,但在大规模代码库处理与安全防护上仍有差距。
- 效率落差:一些团队反馈,使用国内模型时,代码生成准确率与上下文理解能力明显不足。
- 安全隐忧:缺乏内置漏洞检测与合规审查,企业需要额外投入。
案例:某创业团队尝试用国内模型替代GPT-4.5进行代码生成,结果在大型项目中错误率过高,最终不得不回到人工审查,效率下降近40%。
这不是个别现象,而是普遍困境。最强模型的不可及,正在拉大全球开发者的体验差距。

五、未来三年:关键窗口期
为什么说未来三年是关键窗口期?
- 技术迭代周期:大模型通常每12-18个月迭代一次,三年意味着两次迭代窗口。
- 政策规划周期:中国的科技政策往往以三年为阶段目标。
- 生态建设周期:从研发到落地,再到形成开发者习惯,至少需要三年。
因此,三年是一个合理的推测窗口。
机遇在于:
- 政策支持:国家加大算力投资与科研资金。
- 技术突破:国内模型迭代速度加快,Qwen、通义千问等已具备竞争力。
- 开源生态:开源模型与工具链正在形成替代路径。
挑战在于:
- 算力仍受制约。
- 数据语料不足。
- 工具链渗透不够。
结论:未来三年,中国必须在标准化接口、上下文资产、关键场景嵌入三个维度形成突破,否则风险将扩大。

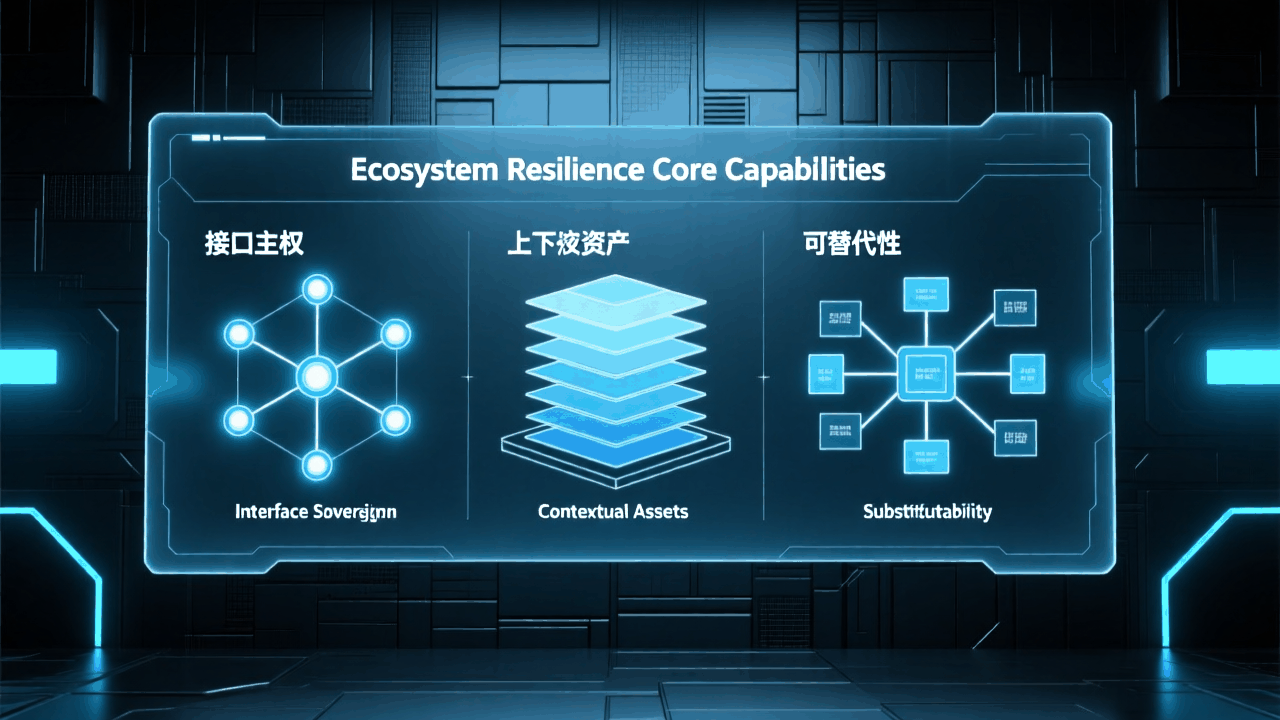
六、关键洞察:生态韧性比性能更重要
真正决定未来的,不是某一个模型,而是整个生态的韧性。
- 接口主权:谁控制接口标准,谁就控制生态。
- 上下文资产:企业的私有代码语料、架构知识图谱、测试数据,决定了对任意模型的适配效率。
- 可降级工作流:保证在模型不可用时,流程仍能运行,这是韧性工程的底线。
- 衡量标准:不仅是准确率,还包括迁移成本、合规负担。
一句话总结:最强模型的发布只是表面,真正的分水岭在于谁掌握接口主权与上下文资产。

七、传播力与思考空间
- 金句:最强模型,却可能是最远的工具。
- 开放性问题:未来三年,中国能否建立自主的代码大模型生态?
这既是传播力的锚点,也是思考的起点。

八、延展思考:开发者的自救与企业的策略
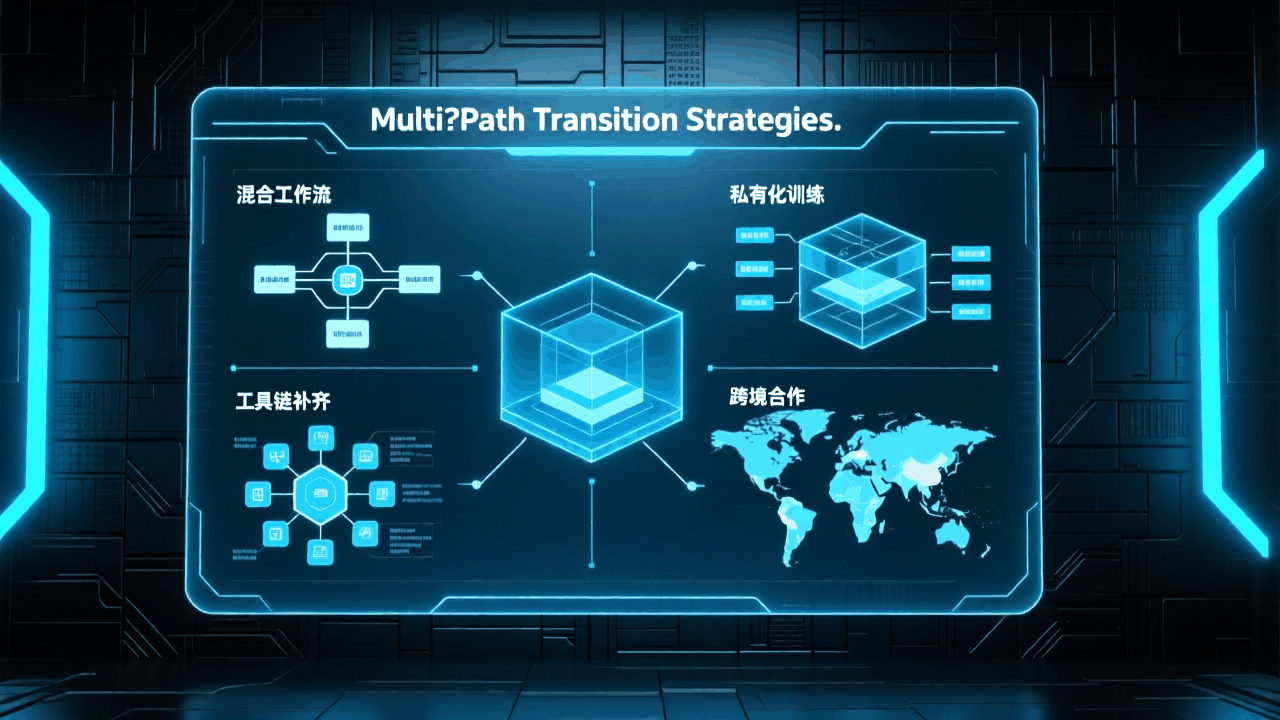
除了等待政策与技术突破,开发者与企业也在探索自救路径:
- 混合工作流:在可访问的场景中使用国际模型,在敏感场景中依赖国内模型。
- 私有化训练:企业基于开源模型进行定制化训练,提升代码生成的针对性。
- 工具链补齐:通过引入安全审查工具、自动化测试框架,弥补国内模型的不足。
- 跨境合作:部分企业尝试与海外团队合作,间接获取模型能力。
这些策略并非完美,但至少为开发者提供了过渡方案。
九、结语
GPT-5.2-Codex的发布,标志着全球开发者进入一个新的生产力时代。但对中国开发者而言,这既是机遇,也是挑战。技术突破与封锁风险的矛盾,正在倒逼中国思考:如何在全球竞争中掌握接口主权,如何在三年窗口期内形成自主生态。
最终,决定未来的不是某一个模型,而是整个生态的韧性与可替换性。只有把开发流程设计为可迁移、可降级、可审计的体系,中国开发者才能在突破与封锁的张力中,获得不被动的生产力。